Computer System Architecture Lab
Computer System Architecture Lab
Home
News
Members
Publications
Research
Gallery
Contact
Light
Dark
Automatic
1
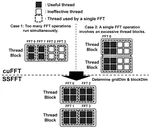
SSFFT: Energy-Efficient Selective Scaling for Fast Fourier Transform in Embedded GPUs
Fast Fourier Transform (FFT) is critical in applications such as signal processing, communications, and AI. Embedded GPUs are often …
Dongwon Yang
,
Jaebeom Jeon
,
Minseong Gil
,
Junsu Kim
,
Seondeok Kim
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
Slides
DOI
Slide Show
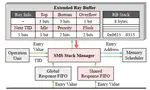
SparsePIM: An Efficient HBM-Based PIM Architecture for Sparse Matrix-Vector Multiplications
Sparse matrix-vector multiplication (SpMV) is a fundamental operation across diverse domains, including scientific computing, machine …
Taewoon Kang
,
Geonwoo Choi
,
Taeweon Suh
,
Gunjae Koo
PDF
Cite
Project
Slides
DOI
Slide Show
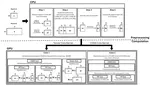
Hierarchical Traversal Stack Design Using Shared Memory for GPU Ray Tracing
Ray tracing is widely used to generate photorealistic images by tracing the paths of light rays through a scene and their interactions …
Eunsoo Jung
,
Eunbi Jeong
,
Gunjae Koo
,
Yunho Oh
,
Myung Kuk Yoon
PDF
Cite
Project
Slides
DOI
Slide Show
HyMM: A Hybrid Sparse-Dense Matrix Multiplication Accelerator for GCNs
Graph convolutional networks (GCNs) are emerging neural network models designed to process graph-structured data. Due to massively …
Hunjong Lee
,
Jihun Lee
,
Jaewon Seo
,
Yunho Oh
,
Myung Kuk Yoon
,
Gunjae Koo
PDF
Cite
Project
Slides
DOI
Slide Show
Poster
Coldmap: Extending SSD Lifetime Exploiting Multi-Page Mapping Information
Solid-state drives (SSDs) include flash translation layer (FTL) functions to manage the inherent characteristics of NAND flash memory. …
Jaewon Seo
,
Gunjae Koo
PDF
Cite
Project
Slides
DOI
Slide Show
VitBit: Enhancing Embedded GPU Performance for AI Workloads through Register Operand Packing
The rapid advancement of Artificial Intelligence (AI) necessitates significant enhancements in the energy efficiency of Graphics …
Jaebeom Jeon
,
Minseong Gil
,
Junsu Kim
,
Jaeyong Park
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
Slides
DOI
Slide Show
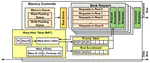
Warped-MC: An Efficient Memory Controller Scheme for Massively Parallel Processors
The performance of GPU’s external memories is becoming more critical since a modern GPU runs thousands of concurrent threads that …
Jonghyun Jeong
,
Myung Kuk Yoon
,
Yunho Oh
,
Gunjae Koo
PDF
Cite
Project
Slides
DOI
Slide Show
CacheRewinder: Revoking Speculative Cache Updates Exploiting Write-Back Buffer
Transient execution attacks are critical security threats since those attacks exploit speculative execution which is an essential …
Jongmin Lee
,
Junyeon Lee
,
Taeweon Suh
,
Gunjae Koo
PDF
Code
Project
Slides
Video
DOI
Slide Show
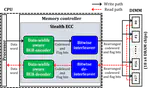
Stealth ECC: A Data-Width Aware Adaptive ECC Scheme for DRAM Error Resilience
As DRAM process technology scales down and DRAM density continues to grow, DRAM errors have become a primary concern in modern data …
Young Seo Lee
,
Gunjae Koo
,
Young-Ho Gong
,
Sung Woo Chung
PDF
Project
Slides
Video
DOI
Slide Show
Restore Buffer Overflow Attacks: Breaking Undo-Based Defense Schemes
Transient execution attacks have been severe security threats since such attacks exploit architectural vulnerabilities in out-of-order …
Jongmin Lee
,
Gunjae Koo
PDF
Cite
Code
Project
Slides
Video
DOI
Slide Show
»
Cite
×