FINEA: An Efficient Neural Network Accelerator Exploiting Factorized Input Features
Abstract
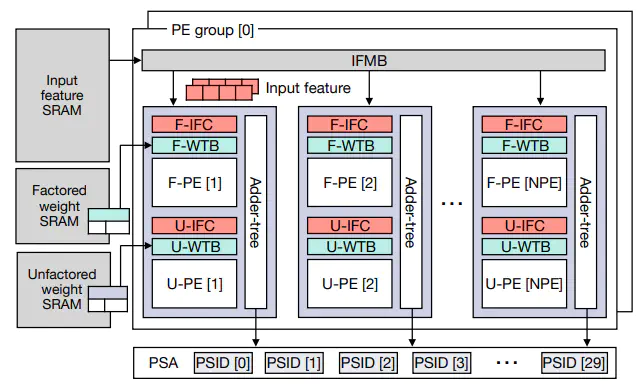
Modern deep neural network (DNN) models increasingly adopt quantized data formats to alleviate the computational burdens of convolution operations. Since quantized models use fewer bits to represent weight parameters and input features, duplicated values often appear within convolution filters. For convolution dot-product operations, we can reduce the number of arithmetic operations if we factorize input feature data with duplicated weight parameters. In this paper, we propose an efficient neural network accelerator architecture, called FINEA, which leverages factorized dot-product operations by exploiting weight redundancy in modern quantized DNN models. By factorizing convolution operations using these duplicated weights, FINEA can significantly reduce the number of required multiplications. To support this factorized approach, FINEA employs a processing engine capable of executing both factorized and unfactorized dotproduct operations. FINEA collects input features using filter indexes derived from preprocessed weight tables. We implement a cycle-accurate simulator to evaluate the performance and hardware cost of the proposed architecture. Our evaluation results show that FINEA outperforms conventional systolic array architectures. FINEA also exhibits higher performance for large models compared to the state-of-the-art flexible architecture. Our cost analysis demonstrates that FINEA is a highly energy-efficient architecture for quantized DNN workloads.