HyMM: A Hybrid Sparse-Dense Matrix Multiplication Accelerator for GCNs
Abstract
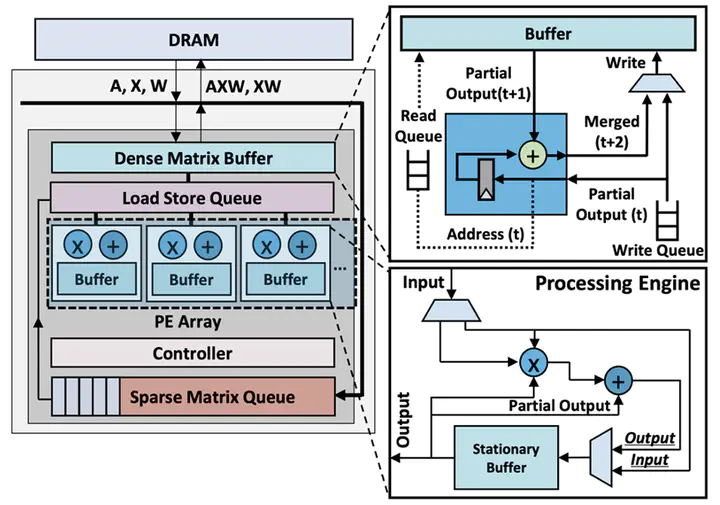
Graph convolutional networks (GCNs) are emerging neural network models designed to process graph-structured data. Due to massively parallel computations using irregular data structures by GCNs, traditional processors such as CPUs, GPUs, and TPUs exhibit significant inefficiency when performing GCN inferences. Even though researchers have proposed several GCN accelerators, the prior dataflow architectures struggle with inefficient data utilization due to the divergent and irregularly structured graph data. In order to overcome such performance hurdles, we propose a hybrid dataflow architecture for sparse-dense matrix multiplications (SpDeMMs), called HyMM. HyMM employs disparate dataflow architectures using different data formats to achieve more efficient data reuse across varying degree levels within graph structures, hence HyMM can reduce off-chip memory accesses significantly. We implement the cycle-accurate simulator to evaluate the performance of HyMM. Our evaluation results demonstrate HyMM can achieve up to 4.78× performance uplift by reducing off-chip memory accesses by 91% compared to the conventional non-hybrid dataflow.