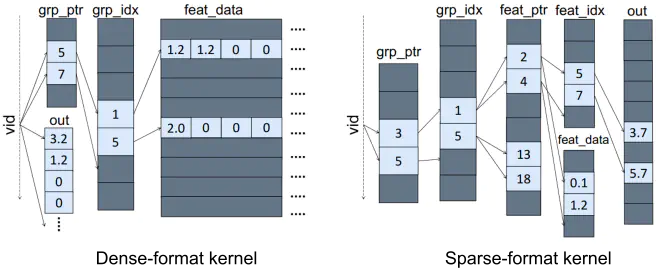
Abstract
Graph convolutional neural networks (GCNs) are emerging neural networks for graph structures that include large features associated with each vertex. The operations of GCN can be divided into two phases - aggregation and combination. While the combination just performs matrix multiplications using trained weights and aggregated features, the aggregation phase requires graph traversal to collect features from adjacent vertices. Even though neural network applications rely on GPU’s massively parallel processing, GCN aggregation kernels exhibit rather low performance since graph processing using compressed graph structures provokes frequent irregular accesses in GPUs. In order to investigate the performance hurdles of GCN aggregation on GPU, we perform an in-depth analysis of the aggregation kernels using real GPU hardware and a cycle-accurate GPU simulator. We first analyze the characteristics of the popular graph datasets used for GCN studies. We reveal the fractions of non-zero elements in feature vectors are diverse among datasets. Based on the observation, we build two types of aggregation kernels that handle uncompressed and compressed feature vectors. Our evaluation exhibits the performance of aggregation can be significantly influenced by kernel design approaches and feature density. We also analyze the individual loads that access the data arrays of the aggregation kernels to specify critical loads. Our analysis reveals the performance of GPU memory hierarchy is influenced by access patterns and feature size of graph datasets. Based on our observations we discuss possible kernel design approaches and architectural ideas that can improve the performance of GCN aggregation.