Abstract
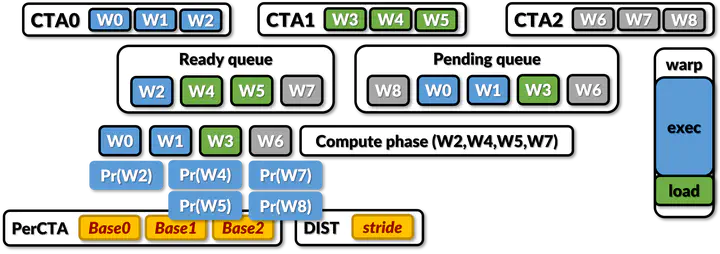
Albeit GPUs are supposed to be tolerant to long latency of data fetch operation, we observe that L1 cache misses occur in a bursty manner for many memory-intensive applications. This in turn leads to severe contentions in GPU memory hierarchy, and thus stalls execution pipeline for many cycles as all warps end up waiting for their memory requests to be serviced by L1 cache. To spread such bursty L1 cache misses, we propose CTA-Aware Prefetcher and Scheduler (CAPS) consisting of a thread group-aware prefetcher and a prefetch-aware warp scheduler for GPUs. GPU kernels group threads into cooperative thread arrays (CTAs). Each thread typically uses its thread index and its associated CTA index to identify the data that it operates on. The starting base address accessed by the first warp in a CTA is difficult to predict since that starting address is a complex function of thread index and CTA index and also depends on how the programmer distributes input data across CTAs. But threads within each CTA exhibit stride accesses. Hence, if the base address of each CTA can be computed early, it is possible to accurately predict prefetch addresses for threads within a CTA. To compute the base address of each CTA, a leading warp is used from each CTA. The leading warp is executed early by pairing it with warps from currently executing leading CTA. The warps in the leading CTA are used to compute the stride value. The stride value is then combined with base addresses computed from the leading warp of each CTA to prefetch the data for all the trailing warps in the trailing CTAs. CAPS allows prefetch requests to be issued sufficiently ahead of time before the demand requests, effectively reorganizing warp executions to quickly detect the base address of each CTA and stride per load. CAPS predicts addresses with over 97% accuracy and is able to improve GPU performance by 8% on average with up to 27% for a wide range of GPU applications.