Communication Optimizations on Large-Scale GPU Clusters Using Rail Optimized Networks and NCCL PXN
Abstract
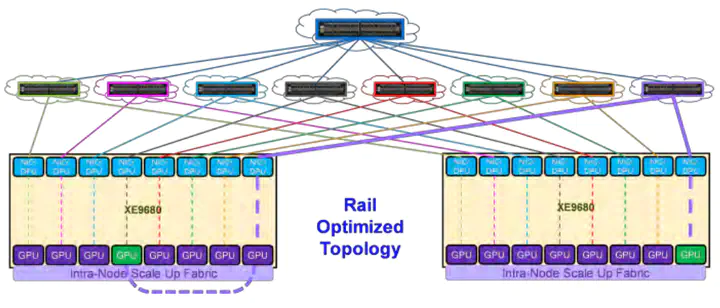
대규모 언어모델을 효율적으로 수행하기 위해서는 여러 대의 GPU 와 CPU 간의 네트워크 통신 최적화가 필요하다. 본 논문에서는 기존의 네트워크 토폴로지 기반 클러스터 구성의 비효율성을 개선하기 위하여 대규모 GPU 클러스터 환경에서 Rail Optimized Network 와 NCCL PXN, NUMA 단순화 및 CPU Affinity 기반의 통신 성능 최적화 기법을 제안한다. 본 연구에서는 제안하는 네트워크 구성 및 라이브러리를 활용하여 Dell XE9680 서버의 4-HCA 구성과 GPU-HCA-CPU 매핑을 통해 집합 통신의 처리량과 지연 시간을 개선하였다. 제안된 방식은 실제 벤치마크를 통해 성능 향상과 확장성을 입증하였으며, 고성능 컴퓨팅 환경에서의 효율적인 네트워크 설계 방향을 제시한다.
Publication
Annual Conference if KIPS