Abstract
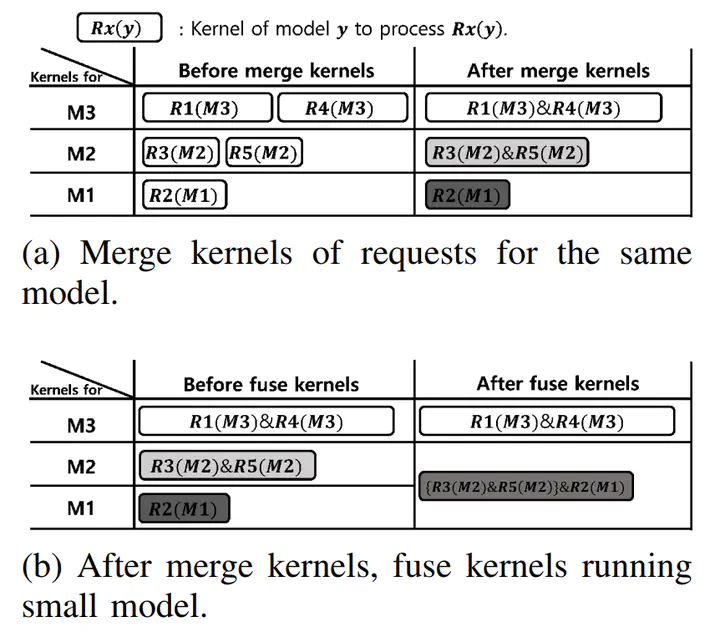
This paper proposes a new scheme that improves throughput and reduces queuing delay while running multiple inferences in embedded GPU-based systems. We observe that an embedded system runs inference with a fixed number of deep learning models and that inference requests often use the same model. Unlike prior work that proposed kernel fusion or scheduling techniques, this paper proposes a new software technique that merges and fuses kernels by monitoring the requests in a queue. The proposed technique first monitors a fixed number of requests and groups the requests running the same model. Then, it creates the kernels that iteratively process the grouped requests. We call such a technique kernel merging. After that, the proposed technique performs kernel fusion with merged kernels. Eventually, our idea minimizes the number of concurrent kernels, thus mitigating stalls caused by frequent context switching in a GPU. In our evaluation, the proposed kernel merge and fusion achieve 2.7× better throughput, 47% shorter average kernel execution time, and 63% shorter tail latency than prior work.