TM-Training: An Energy-Efficient Tiered Memory System for Deep Learning Training in NPUs
Abstract
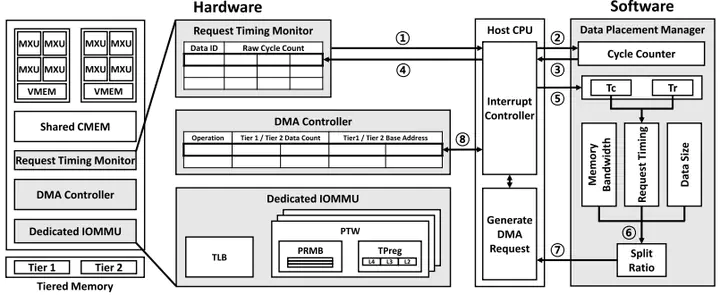
DRAM accounts for a large fraction of the total cost of ownership of memory systems in deep learning acceleration systems. To achieve sustainable scalability, tiered memory systems with denser technologies become critical. Prior work has proposed various tiered memory systems, but no matter how a system is designed, data movements between tiers consume substantial energy. In particular, as model sizes and memory capacity demands grow, the data movements between memory tiers become more frequent, posing a challenge that tiered memory systems may reduce deployment costs but suffer from low energy efficiency. If a memory system proactively places data into a tier and timely fetches it from the tier, then the excessive data movement between tiers can be mitigated. We find that a system can statically anticipate such behaviors for all pages and localities. With this insight, we propose a new DNN acceleration system called TM-Training using flash memory. TM-Training capitalizes on the repetitive nature of the same computational patterns during execution, enabling the static establishment of optimal data placement for subsequent operations. Moreover, TM-Training employs a new data-splitting scheme to enable precise memory management. Our evaluation demonstrates that TM-Training reduces inter-tier data traffic by 64% and achieves a 55% higher throughput per watt in training than prior work.