Performance Analysis of GEMV Kernels by GPU and PIM Memory Address Mapping Approaches
Abstract
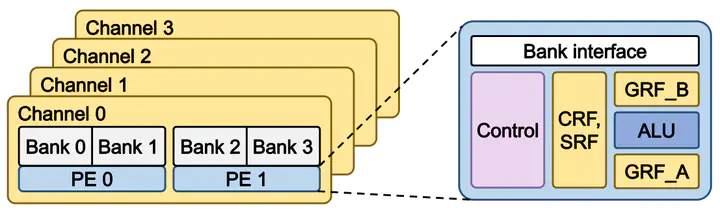
Processing-in-Memory(PIM)은 프로세서와 오프칩(off-chip) 메모리 사이의 대역폭 한계를 극복하기 위한 구조로서 제안되었으며 메모리 내부의 높은 대역폭과 병렬성을 이용하여 정규적인 데이터 연산 성능을 높일 수 있는 구조로 여겨지고 있다. 그렇기 때문에, PIM을 기존의 GPU와 같은 고성능 프로세서에 연결하여 전체적인 성능 향상을 얻을 것으로 기대된다. 그렇지만, PIM과 GPU 구조의 특성에 따른 메모리 주소 매핑 방식의 차이로 인해 메모리 내부의 병렬성을 우선하는 PIM의 주소 매핑 방식을 GPU에 그대로 적용할 경우 전체적인 성능이 하락할 수 있다. 본 논문에서는 메모리 집약적인 행렬-벡터곱(GEMV) 커널 연산을 통해 PIM에 적용된 주소 매핑 방식에 따른 GPU 성능을 분석한다. 분석 결과 PIM의 주소 매핑 방식이 적용된 GPU에서 성능과 대역폭이 하락하여 해당 매핑 방식이 GPU-PIM 구조에서 잠재적 성능 하락의 원인임을 밝혔다.
Publication
Korea Computer Congress