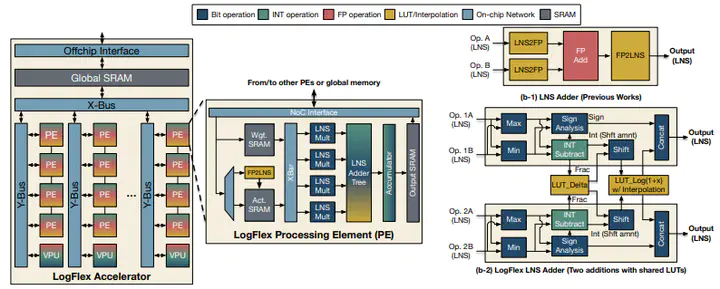
Abstract
Deploying language models (LMs) on resource-constrained mobile/wearable devices while maintaining the output quality is challenging. To address the challenge, many FP and INT quantization methods have been explored. Floating point (FP) arithmetic provide high quality at the cost of heavy area and energy costs, while integer quantized models deliver superior efficiency at the cost of accuracy/perplexity loss. In addition to the design choices between FP and INT, we explore an alternative option based on log number system (LNS), which delivers FP-like accuracy/perplexity at the efficiency close to integer. In addition to applying low-precision (8-bit) LNS, we adaptively assign bits for the integer and fraction depending on the data distribution, which enables near FP16 accuracy/perplexity. We also co-design the LNS arithmetic and accelerator architecture, which leads to 33% less energy than FP8 (E4M3) accelerator with similar area as an INT8 accelerator, while delivering 30% lower perplexity compared to FP8 (E4M3).