SparsePIM: An Efficient HBM-Based PIM Architecture for Sparse Matrix-Vector Multiplications
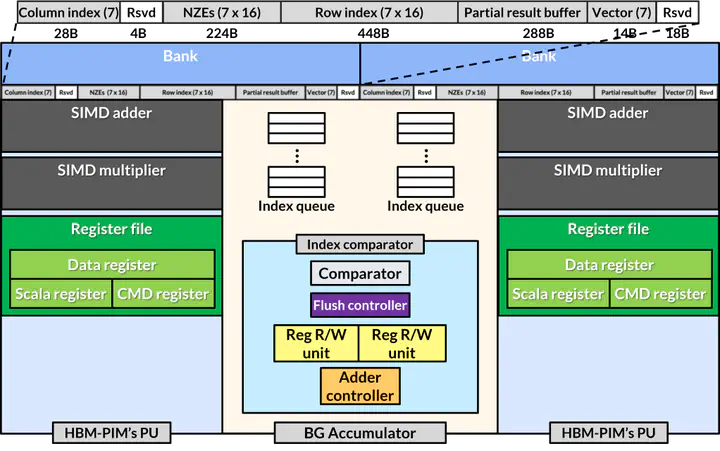 SparsePIM Architecture
SparsePIM Architecture
Abstract
Sparse matrix-vector multiplication (SpMV) is a fundamental operation across diverse domains, including scientific computing, machine learning, and graph processing. However, its irregular memory access patterns necessitate frequent data retrieval from external memory, leading to significant inefficiencies on conventional processors such as CPUs and GPUs. Processing-in-memory (PIM) presents a promising solution to address these performance bottlenecks observed in memory-intensive workloads. However, existing PIM architectures are primarily optimized for dense matrix operations since conventional memory cell structures struggle with the challenges of indirect indexing and unbalanced data distributions inherent in sparse computations. In order to address these challenges, we propose SparsePIM, a novel PIM architecture designed to accelerate SpMV computations efficiently. SparsePIM introduces a DRAM row-aligned format (DRAF) to optimize memory access patterns. SparsePIM exploits K-means-based column group partitioning to achieve a balanced load distribution across memory banks. Furthermore, SparsePIM includes bank group (BG) accumulators to mitigate the performance burdens of accumulating partial sums in SpMV operations. By aggregating partial results across multiple banks, SparsePIM can significantly improve the throughput of sparse matrix computations. Leveraging a combination of hardware and software optimizations, SparsePIM can achieve significant performance gains over cuSPARSE-based SpMV kernels on the GPU. Our evaluation demonstrates that SparsePIM achieves up to 5.61x speedup over SpMV on GPUs.