Computer System Architecture Lab
Computer System Architecture Lab
Home
News
Members
Publications
Research
Gallery
Contact
Light
Dark
Automatic
GPU
Communication Optimizations on Large-Scale GPU Clusters Using Rail Optimized Networks and NCCL PXN
대규모 언어모델을 효율적으로 수행하기 위해서는 여러 대의 GPU 와 CPU 간의 네트워크 통신 최적화가 필요하다. 본 논문에서는 기존의 네트워크 토폴로지 기반 클러스터 구성의 비효율성을 개선하기 위하여 대규모 GPU 클러스터 환경에서 Rail …
Seha Lee
,
Hongil Shin
,
Gunjae Koo
PDF
Cite
Project
Poster
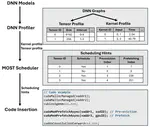
MOST: Memory Oversubscription-Aware Scheduling for Tensor Migration on GPU Unified Storage
Deep Neural Network (DNN) training demands large memory capacities that exceed the limits of current GPU onboard memory. Expanding GPU …
Junsu Kim
,
Jaebeom Jeon
,
Jaeyong Park
,
Sangun Choi
,
Minseong Gil
,
Seokin Hong
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
Project
DOI
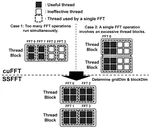
SSFFT: Energy-Efficient Selective Scaling for Fast Fourier Transform in Embedded GPUs
Fast Fourier Transform (FFT) is critical in applications such as signal processing, communications, and AI. Embedded GPUs are often …
Dongwon Yang
,
Jaebeom Jeon
,
Minseong Gil
,
Junsu Kim
,
Seondeok Kim
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
Slides
DOI
Slide Show
Analysis of GEMV Kernel Computations by Address Mapping Approaches Based on GPU and PIM Architectures
Processing-in-Memory (PIM) is an architectural approach that can overcome bandwidth limitations between host processors and off-chip …
Jiwon Shin
,
Gunjae Koo
PDF
Cite
Project
DOI
Hierarchical Traversal Stack Design Using Shared Memory for GPU Ray Tracing
Ray tracing is widely used to generate photorealistic images by tracing the paths of light rays through a scene and their interactions …
Eunsoo Jung
,
Eunbi Jeong
,
Gunjae Koo
,
Yunho Oh
,
Myung Kuk Yoon
PDF
Cite
Project
Slides
DOI
Slide Show
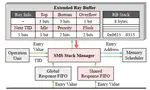
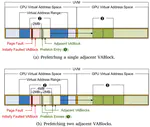
Beyond VABlock: Improving Transformer Workloads through Aggressive Prefetching
The memory capacity constraint of GPUs is a major challenge in running large deep learning workloads with their ever increasing memory …
Jane Rhee
,
Ikyoung Choi
,
Gunjae Koo
,
Yunho Oh
,
Myung Kuk Yoon
PDF
Cite
Project
Project
DOI
TLP Balancer: Predictive Thread Allocation for Multitenant Inference in Embedded GPUs
This letter introduces a novel software technique to optimize thread allocation for merged and fused kernels in multitenant inference …
Minseong Gil
,
Jaebeom Jeon
,
Junsu Kim
,
Sangun Choi
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
DOI
VitBit: Enhancing Embedded GPU Performance for AI Workloads through Register Operand Packing
The rapid advancement of Artificial Intelligence (AI) necessitates significant enhancements in the energy efficiency of Graphics …
Jaebeom Jeon
,
Minseong Gil
,
Junsu Kim
,
Jaeyong Park
,
Gunjae Koo
,
Myung Kuk Yoon
,
Yunho Oh
PDF
Cite
Project
Slides
DOI
Slide Show
Performance Analysis of GEMV Kernels by GPU and PIM Memory Address Mapping Approaches
Processing-in-Memory(PIM)은 프로세서와 오프칩(off-chip) …
Jiwon Shin
,
Gunjae Koo
PDF
Cite
Project
Slides
Slide Show
Conflict-Aware Compiler for Hierarchical Register File on GPUs
Modern graphics processing units (GPUs) leverage a high degree of thread-level parallelism, necessitating large-sized register files …
Eunbi Jeong
,
Eun Seong Park
,
Gunjae Koo
,
Yunho Oh
,
Myung Kuk Yoon
PDF
Cite
Project
DOI
»
Cite
×